Randomly this week I’ve found myself needing to share a local build of Cirros with a simple but unreleased fix included to unblock some testing upstream in OpenStack Nova’s CI.
I’ll admit that it has been a while since I’ve had to personally run any kind of web service (this blog and versions before it being hosted on Gitlab and Github pages) and so I didn’t really know where to start.
I knew that I wanted something that was both containerised and able to
automatically sort out letsencrypt certs so I could
serve the build over https. After trying and failing to get anywhere with
the default httpd and nginx container images I gave up and asked around
on Twitter.
Shortly after a friend recommended Caddy an Apache 2.0 web server written in Go with automatic https configuration, exactly what I was after.
As I said before I wanted a containerised web service to run on my Fedora based VPS, ensuring I didn’t end up with a full service running directly on the host that would be a pain to remove later. Thankfully Caddy has an offical image on DockerHub I could pull and use with Podman, the daemonless container engine and Docker replacement on Fedora.
Now it is possible to run podman containers under a non-root user but as I
wanted to run the service under ports 80 and 443 I had to launch the
container using root. In theory you could adjust your host config to allow
non-root users to create ports below 1024 via
net.ipv4.ip_unprivileged_port_start=$start_port or just use higher ports
to avoid this but I don’t mind running the service as root given the files are
being shared via a read-only volume anyway.
To launch Caddy I used the following commands, obviously with podman already installed and configured.
$ sudo mkdir /run/caddy_data
$ sudo podman run -d -p 80:80 -p 443:443 \
-v $PATH_TO_SHARE:/srv:ro \
-v /run/caddy_data:/data \
--name caddy \
docker.io/library/caddy:latest \
caddy file-server --domain $domain --browse --root /srv
$ sudo podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
65f82d224dde docker.io/library/caddy:latest caddy file-server... 35 hours ago Up 35 hours ago 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp caddy
To ensure the service remained active I also created a systemd service.
$ sudo podman generate systemd -n caddy > /etc/systemd/system/container-caddy.service
Note that at the time of writing on Fedora 33 you need to workaround Podman
issue #8369, replacing the
use of /var/run with /run.
$ sudo sed -i 's/\/var\/run/\/run/g' container-caddy.service
Once that’s done you can enable and start the service just like any other systemd service.
$ sudo systemctl enable container-caddy.service
$ sudo systemctl start container-caddy.service
$ sudo systemctl status container-caddy.service
● container-caddy.service - Podman container-caddy.service
Loaded: loaded (/etc/systemd/system/container-caddy.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2021-03-05 08:38:32 GMT; 9min ago
Docs: man:podman-generate-systemd(1)
Process: 232308 ExecStart=/usr/bin/podman start caddy (code=exited, status=0/SUCCESS)
Main PID: 230641 (conmon)
Tasks: 0 (limit: 9496)
Memory: 892.0K
CPU: 129ms
CGroup: /system.slice/container-caddy.service
‣ 230641 /usr/bin/conmon --api-version 1 -c 65f82d224dde0ba6342ac4e1b2e9b61d26d2f7efe887fb08b18632cf849a1ace -u 65f82d224dde0ba6342a>
Mar 05 08:38:32 $domain systemd[1]: Starting Podman container-caddy.service...
Mar 05 08:38:32 $domain systemd[1]: Started Podman container-caddy.service.
As we used the --browse flag when launching Caddy you should now find a
simple index page listing your files.
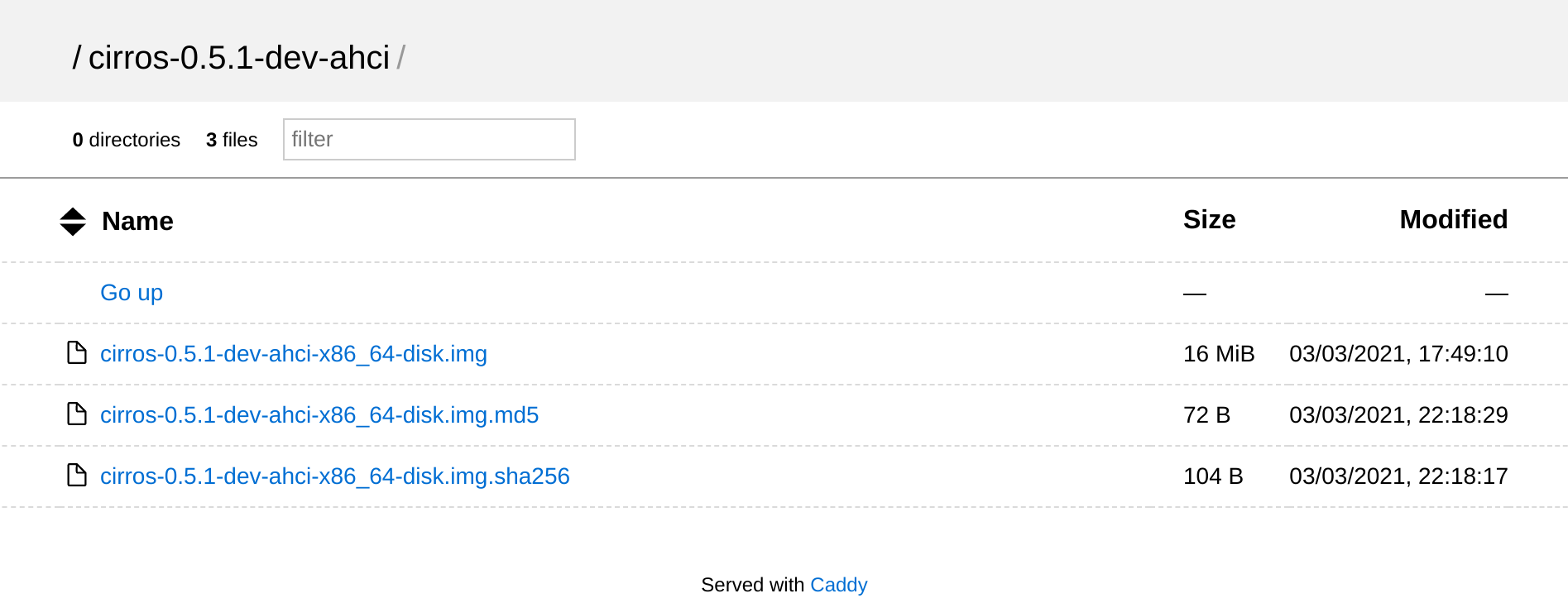
That’s it, simple, fast and hopefully easy to cleanup when I no longer need to share these files. Maybe I should ask for suggestions on Twitter more often!