Welcome to part #7 of this series tracking the development of instance types and preferences in KubeVirt!
Following on from Update #6, this post covers key features, improvements, and bug fixes introduced across the KubeVirt v1.8.0 and v1.9.0 release cycles, as well as ongoing work on main.
VirtualMachinePreference authors can now define a preferred video device type (virtio, vga, bochs, ramfb) under spec.devices.preferredVideoType (PR #16812):
When a VirtualMachine includes a video device without an explicit type field, the preference automatically sets the preferred video model.
PreferredLaunchSecurity and Deprecation in Instancetypes
Launch security settings (such as AMD SEV / SEV-ES / SEV-SNP or IBM Secure Execution) have been moved into preferences via spec.preferredLaunchSecurity (PR #17551):
Concurrently, spec.launchSecurity in VirtualMachineInstancetype has been deprecated and will be removed in a future API version, consolidating hardware security defaults within the preference API where they belong.
Panic Device Creation Fix
While PreferredPanicDeviceModel previously existed in preferences, setting it on a VirtualMachine without an explicit panic device would silently ignore the preference. Preference application now automatically creates a panic device with the requested model when PreferredPanicDeviceModel is specified (PR #18314, addressing Issue #18305).
Required Architecture Requirement
In addition to preferredArchitecture (which defaults vmiSpec.Architecture if unassigned), preferences now support enforcing a strict architecture requirement via spec.requirements.architecture (PR #15398):
When a VirtualMachine references a preference with spec.requirements.architecture, KubeVirt’s validation webhook enforces that the VM’s requested architecture matches. If a mismatch is detected (or if the VM specifies an incompatible architecture like amd64), the webhook rejects the creation with a clear validation error (preference requires architecture arm64 but amd64 is being requested).
Inference Enhancements
inferFromVolume Support for VolumeSnapshot Sources
The inferFromVolume mechanism allows KubeVirt to automatically detect and apply instance types and preferences from labels on underlying storage. Support has now been extended beyond PVCs and DataVolumes to include VolumeSnapshot-backed sources (PR #18337, refactored in PR #18339):
When dv-from-snapshot uses a VolumeSnapshot source, KubeVirt now inspects the snapshot’s labels to resolve matching instance types and preferences seamlessly.
Common Instancetypes Bundles
virt-operator deployment of common-instancetypes has been updated to track v1.6.0 (PR #16705) and v1.7.0 (PR #18228) release bundles, ensuring standard instance types and OS preferences (RHEL, Fedora, CentOS, Ubuntu, Windows) are deployed and updated out of the box.
Internal bundle manifest management in virt-operator was also restructured to simplify bundle updates and reduce release overhead (PR #16546).
Controller Stability & Bug Fixes
ResourceVersion Propagation: Fixed a race condition where PatchStatus responses were discarding server-side ResourceVersion updates during instancetype synchronization, preventing status conflicts during VM sync loops (PR #16498, fixing Issue #16496).
ControllerRevision Matcher Handling: Corrected ControllerRevisionRef capture when matchers are nil (Issue #16071).
Test Suite Modernization
The instancetype test suite underwent significant refactoring (PR #17031, PR #16228):
Migrated legacy E2E tests into fast unit test suites (inference_test.go, webhook_test.go, revisions_test.go, requirements_test.go).
Standardized test setup using KubeVirtTestSuiteSetup and Ginkgo matchers for improved maintainability.
Following on from my release-1.8 AI attribution
review, I’ve
repeated the analysis for the release-1.9 development cycle. The results show
a dramatic shift in AI tooling adoption across the project.
Background
KubeVirt’s AI Contribution
Policy
asks contributors to disclose AI-assisted work using git trailers such as
Assisted-by:, Co-authored-by:, or Generated-by:. This review covers the
commit range origin/release-1.8..origin/release-1.9 (the v1.9.0 development
cycle).
Overview
Metric
1.9
1.8
Total commits
1,564
1,089
Merge commits
505
351
Non-merge commits
1,059
738
Commits with AI attribution
536
76
AI-attributed share (of non-merge)
50.6%
10.3%
Distinct contributors using AI
38
15
DCO (Signed-off-by) compliance
536/536 (100%)
76/76 (100%)
The headline number: half of all non-merge commits now carry AI
attribution. That’s a 7x increase in absolute count and a nearly 5x increase
in share compared to release-1.8. The number of contributors using AI tooling
has grown from 15 to 38. DCO compliance remains perfect at 100%.
AI Tools Used
Tool
Commits
Authors
Claude (all variants)
469
35
Cursor
72
9
GPT / Codex
16
1
Gemini
7
2
Composer (Anysphere)
5
2
sourcery-ai
3
3
IBM Bob
2
2
Note: some commits reference multiple tools, so the per-tool totals exceed 536.
Claude remains dominant but the ecosystem has diversified significantly. In 1.8,
only Claude and Cursor appeared. In 1.9, seven distinct AI tools or platforms
are represented. Claude accounts for ~87% of commits using AI, Cursor for ~13%,
with GPT/Codex, Gemini, Composer, sourcery-ai, and IBM Bob making up the tail.
An interesting new pattern is contributors specifying the underlying model when
using Cursor, e.g. Assisted-by: Cursor (claude-4.6-opus-high-thinking) or
Assisted-by: Cursor (gpt-5.3-codex-high). This gives finer-grained
visibility into what models are being used through editor-integrated AI.
94.4% of AI-attributed commits come from Red Hat engineers (33 of 38
contributors), consistent with the 1.8 pattern. Nvidia, IBM, and community
contributors make up the remainder.
PR Quality: AI vs Non-AI
I pulled metrics for 219 AI-attributed PRs and 284 non-AI PRs merged during the
cycle via the GitHub API.
Time to Merge
Metric
AI PRs
Non-AI PRs
Median
13.0 days
9.0 days
Mean
25.3 days
25.5 days
Unlike 1.8, where AI PRs merged slightly faster, the pattern has shifted. AI
PRs now take longer on median (13.0 vs 9.0 days), though the mean is virtually
identical. When controlled for PR size, the picture is more nuanced:
Size Bucket
AI PRs
Non-AI PRs
Small (<50 lines)
7.5 days
2.8 days
Medium (50-200 lines)
13.7 days
18.7 days
Large (200+ lines)
23.9 days
18.5 days
Medium AI PRs merge notably faster (13.7 vs 18.7 days), consistent with the 1.8
finding. Small AI PRs take considerably longer than small non-AI PRs (7.5 vs 2.8
days), which may reflect that even “small” AI-assisted changes tend to be more
substantive and require more review than typical small fixes. Large AI PRs take
longer (23.9 vs 18.5 days), possibly reflecting the increased review burden of
large AI-generated diffs that was flagged in the 1.8 review.
PR Size
Metric
AI PRs
Non-AI PRs
Median additions
49
23
Median deletions
15
8
Median changed files
3
3
AI PRs continue to skew larger, with 30% at size L or above (vs 25% for
non-AI), though the gap is narrower than in 1.8 (where 65% of AI PRs were L+).
13 AI-attributed PRs reference VEPs, including work on Node Hooks (VEP-190),
multi-architecture software emulation (VEP-172), and NAD hotplug.
Changes Requested
Rounds
AI PRs
Non-AI PRs
0
195 (89%)
258 (91%)
1+
24 (11%)
26 (9%)
The change-request rate for AI PRs has ticked up slightly to 11% (from 9% in
1.8), while non-AI PRs remain at 9%. This is a marginal difference and not
statistically significant at these sample sizes, but worth continuing to
monitor.
Review Intensity
Size Bucket
AI PRs
Non-AI PRs
Small (<50 lines)
0.0
0.0
Medium (50-200 lines)
4.9
4.8
Large (200+ lines)
1.5
1.7
(Median comments per 100 lines changed)
This is a notable improvement from 1.8. In the previous cycle, large AI PRs
received significantly fewer comments per line than non-AI PRs (2.5 vs 6.2),
raising questions about whether reviewers were scrutinizing AI-generated diffs
less carefully. In 1.9, the review intensity for large PRs is essentially
identical (1.5 vs 1.7). Medium PRs are also nearly identical (4.9 vs 4.8). The
review depth concern from 1.8 appears to have resolved itself.
Statistical Analysis
The median comparisons above are useful for intuition, but they don’t tell us
whether the differences are statistically meaningful or just noise. To go
deeper, I computed Cliff’s
delta
(a non-parametric effect size measure suitable for skewed data like
time-to-merge), Mann-Whitney U tests for significance, and Benjamini-Hochberg
corrections for multiple comparisons. I also computed three complexity metrics
beyond lines changed: directory entropy, test code ratio, and distinct
subsystems touched.
Effect Sizes
Metric
AI median
Non-AI median
Cliff’s δ
Magnitude
p (BH)
Time to merge (days)
13.0
9.0
+0.147
small
0.009
Total lines changed
84
40
+0.168
small
0.004
Additions
49
23
+0.149
small
0.009
Deletions
15
8
+0.087
negligible
0.135
Changed files
3
3
+0.088
negligible
0.135
Test code ratio
0.65
0.29
+0.238
small
<0.001
Directory entropy
0.23
0.02
+0.052
negligible
0.360
Subsystems touched
2
2
+0.047
negligible
0.368
Review comments
3
0
+0.191
small
<0.001
Changes requested
0
0
+0.018
negligible
0.512
Cliff’s delta ranges from -1 to +1. Positive values mean AI PRs have higher
values. Per Romano et al. (2006), |δ| < 0.147 is negligible, 0.147-0.33 is
small, 0.33-0.474 is medium, and ≥ 0.474 is large.
The key takeaway: most differences between AI and non-AI PRs are negligible to
small. The statistically significant differences (after BH correction at
q=0.05) are:
Total lines changed (δ=+0.168, small) — AI PRs are moderately larger
Time to merge (δ=+0.147, small) — AI PRs take slightly longer, but this is
right at the negligible/small boundary
Test code ratio (δ=+0.238, small) — AI PRs contain proportionally more test
code (median 65% vs 29%)
Review comments (δ=+0.191, small) — AI PRs receive more review comments in
absolute terms
The test code ratio finding is striking. AI-attributed PRs have a median test
code ratio of 65% vs 29% for non-AI PRs. This suggests AI tooling is being used
particularly for writing tests, or that contributors using AI are more diligent
about test coverage.
Notably, changes requested (δ=+0.018), directory entropy (δ=+0.052), and
subsystems touched (δ=+0.047) are all negligible — AI PRs are not generating
more reviewer pushback, and their structural complexity (how spread out changes
are across the codebase) is indistinguishable from non-AI PRs.
Complexity Metrics
Metric
AI PRs
Non-AI PRs
Directory entropy (median)
0.23
0.02
Directory entropy (mean)
0.66
0.55
Test code ratio (median)
0.65
0.29
Test code ratio (mean)
0.59
0.41
Subsystems touched (median)
2
2
Subsystems touched (mean)
3.1
2.5
Directory entropy (Shannon entropy over the distribution of changed lines across
directories) measures how spread out changes are. Higher values indicate changes
touching more parts of the codebase. The difference in medians looks large (0.23
vs 0.02) but the effect size is negligible (δ=+0.052), meaning many non-AI PRs
also have higher entropy — the distributions overlap heavily.
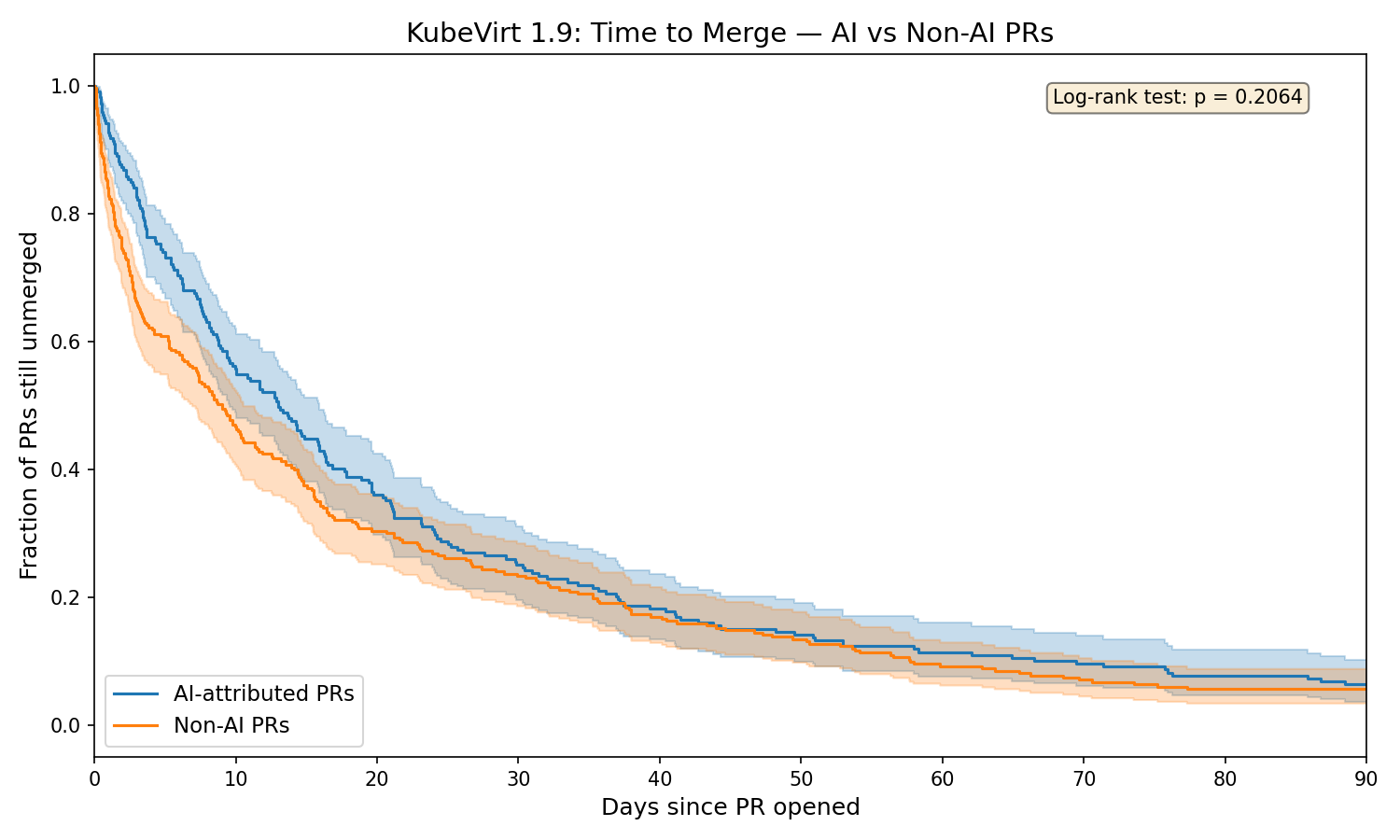
Kaplan-Meier Survival Analysis
A more rigorous way to compare merge timelines is Kaplan-Meier survival
analysis, which shows what fraction of PRs remain unmerged over time:
The curves diverge early — non-AI PRs merge faster in the first ~15 days — then
converge. The log-rank test gives p=0.206, meaning the overall difference in
merge time distributions is not statistically significant. While the median
TTM differs (13.0 vs 9.0 days), the full distributions are not distinguishable
at conventional significance levels.
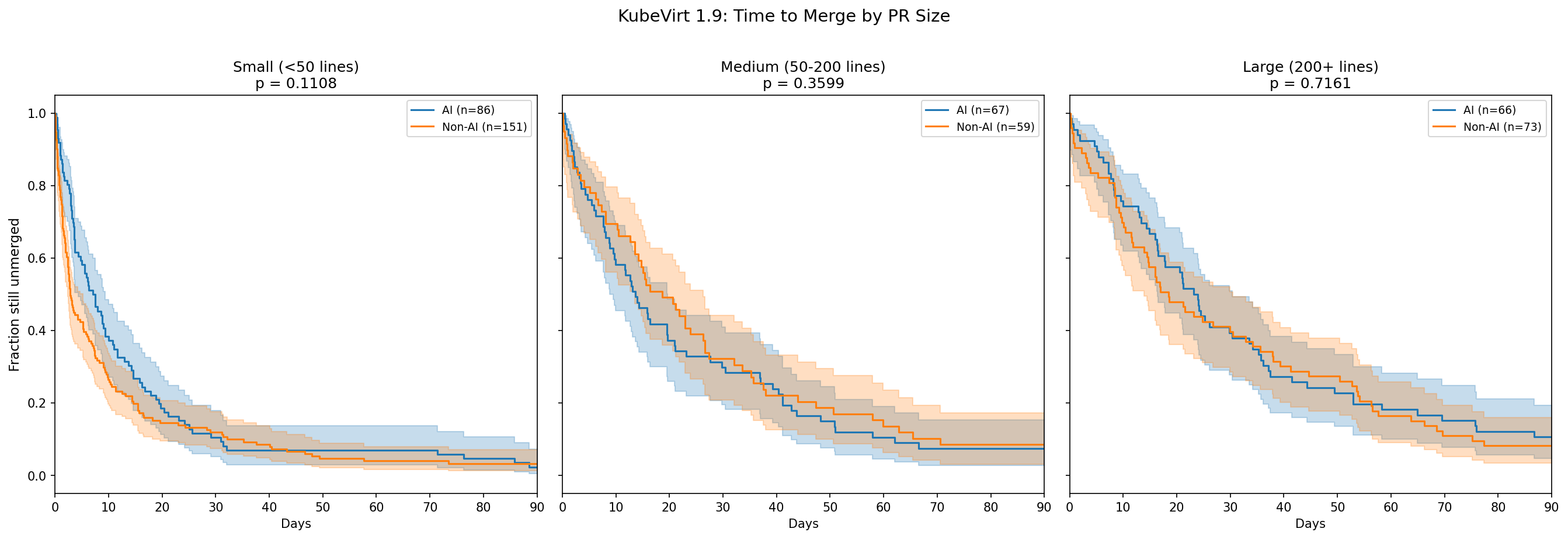
When stratified by PR size, the picture becomes clearer:
Small PRs: The visible gap (AI slower) has a small effect size
(δ=+0.238, p=0.002). Small AI PRs genuinely take longer, likely because they
are more substantive than typical small non-AI changes.
Medium PRs: No significant difference (δ=-0.073, p=0.485). AI and non-AI
medium PRs merge at essentially the same rate.
Large PRs: No significant difference (δ=+0.055, p=0.579). Despite the
5-day median difference (23.5 vs 18.5), the distributions overlap too much
for this to be meaningful.
Methodology Note
The analysis uses Cliff’s delta rather than Cohen’s d because time-to-merge and
comment counts are heavily right-skewed (not normally distributed). Mann-Whitney
U provides non-parametric significance tests, with Benjamini-Hochberg correction
for the 10 comparisons. Kaplan-Meier analysis uses the
lifelines library with log-rank tests. The
full analysis script is available alongside the raw data in the report
repository.
Trailer Format: Still the Main Issue
The format inconsistency flagged in the 1.8 review has gotten worse in absolute
terms. There are now 59 distinct trailer value formats across 536 commits,
up from 17 formats across 76 commits. Some examples:
Format
Count
Notes
Assisted-by: Claude <noreply@anthropic.com>
71
Matches policy
Assisted-by: Claude Opus 4.6 <noreply@anthropic.com>
57
Includes model
Assisted-By: Claude <noreply@anthropic.com>
42
Case variant
Assisted-by: claude-4.6-opus
42
Model slug, no email
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
39
Assisted-By: Claude Sonnet 4.6
35
No email
Assisted-By: Claude opus 4.6 <noreply@anthropic.com>
33
Lowercase model
Assisted-by: Cursor
29
No email
Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
18
Includes context window
Assisted-By: Claude Sonnet 4.6 via Cursor
14
Dual tool
Assisted-by: Claude Sonnet 4.6 <noreply@anthropic.com>
14
…
47 more variants
Key inconsistencies that make machine parsing difficult:
Case variation: Assisted-by vs Assisted-By vs Co-Authored-By vs Co-authored-by
Model name inclusion: ~60% include the model name, ~40% don’t
Email format: some use <noreply@anthropic.com>, some use <claude@anthropic.com>, some omit email entirely
Context window annotation: some include (1M context) in the model name
Cursor model specification: some note the underlying model (Cursor (claude-4.6-opus-high-thinking)), most don’t
Tool chain notation: Claude Sonnet 4.6 via Cursor vs separate trailers for each tool
The Generated-by: trailer defined in the policy remains unused in 1.9, same as 1.8.
Comparison with 1.8
Metric
1.8
1.9
Change
AI-attributed commits
76
536
+605%
AI share of non-merge
10.3%
50.6%
+40.3pp
Contributors using AI
15
38
+153%
AI tools represented
2
7
+250%
Distinct trailer formats
17
59
+247%
AI PR median TTM
7.5 days
13.0 days
+5.5 days
Changes requested (AI)
9%
11%
+2pp
Large PR review depth gap
2.5 vs 6.2
1.5 vs 1.7
Closed
Recommendations
The 1.8 review made five recommendations. Here’s the status and updated guidance:
Standardize trailer formats - Not implemented. With 59 formats across 536
commits, this is now urgent. A git interpret-trailers alias or commit hook
should be provided to enforce 1-2 canonical formats.
Clarify model name inclusion - Not resolved. The split has shifted but
remains inconsistent. The policy should either require or discourage model
name inclusion.
Add CI validation - Not implemented. A prow check for trailer format
would catch the 59 format variants before merge.
Monitor review depth on large AI PRs - The gap has closed. Large AI PRs
now receive essentially identical review intensity to non-AI PRs. This
concern can be downgraded but should continue to be tracked.
Continue tracking metrics across releases - This review does exactly that,
and the trend data is already proving valuable.
Additional recommendations for 1.10:
Address multi-tool attribution - Contributors using Claude through Cursor
are handling this inconsistently (separate trailers, combined trailers, or
only mentioning one tool). The policy should provide guidance.
Consider the review load - With half of all commits now AI-attributed and
AI PRs skewing larger, the review burden has increased substantially. The
project should discuss whether review processes need to adapt.
Conclusion
The 1.9 cycle represents an inflection point for AI tooling adoption in KubeVirt.
Moving from 10% to 50% of non-merge commits carrying AI attribution in a single
release cycle is a remarkable shift. The data shows this isn’t concentrated among
a few contributors — 38 distinct developers are now using AI tools, up from 15.
The quality story is broadly positive: DCO compliance is perfect, review
intensity has normalized, and statistical analysis confirms that most differences
between AI and non-AI PRs are negligible to small in effect size. The most
interesting finding is that AI PRs contain proportionally more test code (median
65% vs 29%), suggesting AI tooling is being used to improve test coverage. The
ecosystem has diversified beyond Claude and Cursor to include GPT/Codex, Gemini,
Composer, sourcery-ai, and IBM Bob, though Claude remains dominant at ~87% of
commits.
The main action item remains trailer format standardization. With 59 distinct
formats, the attribution data is becoming increasingly difficult to parse
programmatically. Implementing the trailer standardization and CI validation
recommended in the 1.8 review should be a priority before the 1.10 cycle.
The Ambient Code Platform gives you managed AI coding sessions backed by real workspaces, but the web UI isn’t always where I want to be when I’m already living in the terminal. So I built acptui — a terminal UI for browsing and managing Ambient Code Platform sessions without leaving the shell.
What it does
acptui starts with a project picker listing every project you have access to. Selecting one drops you into a session list showing phase, model, repo, and age at a glance. From there you can create, start, stop, or delete sessions, open a live chat view with streaming responses, browse workspace files, or check on background tasks — all without touching a browser.
The chat view streams assistant responses over SSE in real time, including collapsible thinking blocks you can expand with tab. You can export any conversation to markdown with ctrl+e, or open the session in the web UI with w if you need the full interface.
Session management from the CLI
Beyond the TUI, acptui create lets you spin up sessions programmatically:
There’s also acptui export for dumping conversations to markdown and acptui login for browser-based OpenShift OAuth authentication.
Filtering
The filter bar supports regex and field-specific prefixes, same pattern as cctv:
phase:Running # match session phase
model:sonnet # match model name
repo:github.com/org/repo # match repository URL
phase:Running model:sonnet # multiple terms ANDed
Stack
Written in Go using the same Charm libraries as cctv — Bubble Tea for the TUI, Lip Gloss for styling, and Cobra for the CLI. Ships with five color themes (default, catppuccin, dracula, nord, light). Tests use Ginkgo.
KubeVirt development involves a lot of repetitive workflow — reviewing PRs against project conventions, triaging CI failures across dozens of job lanes, tracking enhancement proposals through the release process. These tasks are well-defined but time-consuming, and they’re exactly the kind of thing an AI coding assistant can help with if you give it the right context.
kubevirt-ai-helpers is a collection of Claude Code plugins that encode KubeVirt-specific knowledge into reusable slash commands. Instead of pasting reviewer checklists or manually crawling Prow logs, you run a command and get structured output that follows the project’s conventions.
What’s in the box
The main plugin ships 18 commands organized around four areas of KubeVirt development:
Code review — /kubevirt:review runs a multi-pass review of your local branch changes (general design, detailed code, standards compliance, commit history). /kubevirt:review-pr does the same against a remote PR via the gh CLI, posting pending review comments with verified line numbers so you can edit before submitting.
CI analysis — /kubevirt:ci-health gives a quick overview of failure trends across merge-time jobs using pre-aggregated data from kubevirt/ci-health. /kubevirt:ci-lane digs deeper into a specific job with live Prow data. /kubevirt:ci-search finds test failures by regex pattern across all jobs, and /kubevirt:ci-triage layers on root cause analysis with cross-job correlation. /kubevirt:review-ci ties it back to a specific PR, categorizing its failures and suggesting fixes.
VEP management — KubeVirt Enhancement Proposals have their own lifecycle tracked across GitHub issues, PRs, and project boards. /kubevirt:vep-list shows open proposals with release tracking status. /kubevirt:vep-summary gives a TL;DR of any VEP. /kubevirt:vep-groom reviews a proposal PR against template requirements. /kubevirt:vep-find-reviewers identifies potential reviewers based on SIG ownership and recent git activity.
Development workflow — /kubevirt:dev implements what I’ve been calling the “harness pattern”: it loads project conventions and code context upfront (feedforward), then iterates through build, test, lint, and self-review sensors (feedback) to converge on correct code. It accepts GitHub issues, Jira tickets, or plain text as input and produces a development session with changes ready to commit.
How it works
These are Claude Code plugins — markdown files with structured frontmatter that Claude Code loads as slash commands. Each command is essentially a detailed prompt that encodes project-specific knowledge: reviewer checklists, coding conventions, CI infrastructure details, and the VEP process. When you invoke a command, Claude Code follows the steps in the prompt, using its tools (file reads, shell commands, gh CLI) to gather context and produce output.
There’s no custom runtime or API. The plugins run inside Claude Code’s existing agent loop, which means they get tool use, context management, and conversation history for free.
claude plugins:install kubevirt/kubevirt-ai-helpers
Or clone the repo and point Claude Code at it locally. Commands are available immediately as /kubevirt:* slash commands.
Contributing
The project has 36 contributors so far. The plugin architecture makes it straightforward to add new commands — each one is a self-contained markdown file with frontmatter defining its name, arguments, and description, followed by the implementation steps. The hello-world plugin serves as a reference template.
I’ve been using Claude Code heavily over the past few months and one thing that kept bugging me was how hard it is to find and resume old conversations. The built-in --resume picker works but it’s minimal — no filtering, no metadata at a glance, and no way to search across projects.
So I built cctv — a terminal UI for browsing and resuming Claude Code conversations from the local filesystem.
Why bother resuming?
Claude Code conversations accumulate context as you work — files discussed, decisions made, bugs investigated. Starting fresh throws all of that away. Resuming a session means:
No re-explaining — Claude already knows your codebase, what you tried, and what’s left
Cheaper — resumed sessions carry their prompt cache forward, so Claude doesn’t re-read everything from scratch
Better coherence — pick up hours or days later and the conversation still knows what was agreed
What it does
cctv reads Claude Code’s local storage (~/.claude/) and presents all your sessions in a searchable, filterable list. Each session shows its summary, project, git branch, linked PRs, message count, and when it was last active. Running sessions are highlighted.
Pressing Enter on a session launches claude --resume — cctv suspends, Claude takes over the terminal, and when you’re done, cctv comes back. You can also pop open a stats view showing token usage and cache hit rates, or drill into the detail view for prompt history and model info.
Filtering
The filter bar supports regex and field-specific prefixes:
project:kubevirt$ # exact project name
branch:^feature/ # branches starting with feature/
pr:enhancements#242 # by PR repo or number
project:backend branch:main # multiple terms ANDed
There’s also a non-interactive cctv list command with --json output for scripting, and all the same filter flags (--project, --branch, --pr, --cwd, --pwd).
This was built around my own workflow so I’ve almost certainly missed use cases. If you have ideas for new filters, views, or features — or if you spot something that doesn’t work with your Claude Code setup — issues and PRs are very welcome.
Earlier today I ran a review of AI attribution adoption on the KubeVirt
release-1.8 branch against the KubeVirt AI Contribution
Policy.
The full report is available
here,
but I wanted to share some of the highlights and takeaways in this post.
Background
KubeVirt adopted an AI Contribution
Policy
asking contributors to disclose AI-assisted work using git trailers such as
Assisted-by:, Co-authored-by:, or Generated-by:. The policy emphasises
transparency, human oversight, and community review rather than mandating
specific workflows. This review covers the commit range
release-1.7..release-1.8 (the v1.8.0 development cycle) to see how well the
policy is being adopted and what the data tells us about AI-assisted
contributions.
Overview
Metric
Count
Total commits
1,089
Merge commits
351
Non-merge commits
738
Commits with AI attribution
76
AI-attributed share (of non-merge)
10.3%
Distinct contributors using AI
15
DCO (Signed-off-by) compliance
76/76 (100%)
10.3% of non-merge commits now carry AI attribution, with 15 distinct
contributors using AI tooling. Every single AI-attributed commit has a valid
Signed-off-by, so DCO compliance is perfect.
AI Tools Used
Tool
Trailer Instances
Authors
Claude (all variants)
70
11
Cursor
14
7
Claude dominates at ~83% of all AI attribution instances, with the majority of
commits using either Claude Code or
the Claude web interface. Cursor accounts for the remainder.
98.7% of AI-attributed commits come from Red Hat engineers, likely reflecting
both Red Hat’s large contribution share and potentially earlier internal adoption
of the policy.
PR Quality: AI vs Non-AI
This is the most interesting part of the review. I pulled metrics for 35
AI-attributed PRs and 315 non-AI PRs merged during the cycle via the GitHub API.
Time to Merge
Metric
AI PRs
Non-AI PRs
Median
7.5 days
8.9 days
Mean
14.3 days
22.9 days
AI PRs merge slightly faster on median. When controlled for PR size, medium PRs
(50-200 lines) with AI attribution merge notably faster (8.7 vs 13.0 days
median), while small and large PRs show no significant difference.
PR Size
Metric
AI PRs
Non-AI PRs
Median additions
88
24
Median deletions
17
11
Median changed files
5
3
AI-attributed PRs skew larger, with 65% at size L or above. This suggests AI
tooling is being used for substantial work rather than trivial changes. 7 of the
35 AI PRs implement approved
VEPs, including features like
Containerpath Volumes and Passt as a beta core networking backend.
Changes Requested
Rounds
AI PRs
Non-AI PRs
0
32 (91%)
288 (91%)
1+
3 (9%)
27 (9%)
The rate of PRs receiving formal “changes requested” reviews is identical at 9%
for both AI and non-AI PRs. AI-attributed contributions are not generating more
reviewer pushback than human-only contributions.
Review Intensity
One metric that warrants monitoring is review depth on large PRs. When looking at
comments per 100 lines changed:
Size Bucket
AI PRs
Non-AI PRs
Small (<50 lines)
35.4
100.0
Medium (50-200 lines)
15.4
15.0
Large (200+ lines)
2.5
6.2
For medium PRs the review intensity is essentially identical. For large PRs,
AI-attributed changes receive fewer comments per line (2.5 vs 6.2). This could
indicate cleaner code or it could suggest reviewers spend less time per line on
large AI-generated diffs. This is worth tracking over future releases.
Trailer Format: The Main Issue
While the policy is being adopted, the format of the attribution trailers
is all over the place. There are 17 distinct trailer value formats across
only 76 commits:
Format
Count
Notes
Assisted-By: Claude <noreply@anthropic.com>
21
Matches policy example
Assisted-by: Claude <noreply@anthropic.com>
19
Matches policy (case variant)
Co-authored-by: Cursor <cursoragent@cursor.com>
7
Auto-added by Cursor
Co-Authored-By: Claude Opus 4.5 <noreply@anthropic.com>
5
Includes model name
Assited-by: Claude Sonnet 4.5 <noreply@anthropic.com>
4
Typo in trailer name
Assisted-by: claude-4.5-opus
4
Missing email, uses model slug
…
12 more variants
Contributors vary by including model names, using model ID slugs, omitting email
addresses, and in one case misspelling the trailer name as Assited-by. The
Generated-by: trailer defined in the policy was never used at all.
Recommendations
Based on this review I’d suggest the project consider:
Standardize trailer formats - Define 1-2 canonical formats and provide a
git interpret-trailers alias or commit hook to enforce them.
Clarify model name inclusion - Currently ~30% of Claude attributions
include the model variant, ~70% don’t. The policy should take a position.
Add CI validation - A prow check that validates AI attribution trailer
format would catch typos and non-standard formats before merge.
Monitor review depth on large AI PRs - The lower comment-per-line rate on
large AI PRs isn’t necessarily a problem today but should be tracked over time.
Continue tracking these metrics across releases - This release-1.8
baseline can be compared against future releases to identify trends.
Conclusion
The overall picture is positive. Contributors are voluntarily adopting
KubeVirt’s AI Contribution Policy, DCO compliance across AI-attributed commits
is perfect, and the data shows no measurable quality difference between
AI-attributed and non-AI PRs. AI tooling is being used for
substantial work across core subsystems, not just boilerplate. The main area for
improvement is standardizing the trailer format to make attribution data more
consistent and machine-parseable.
The full report with all the raw data is available
here.
Welcome to part #6 of this series following the
development of instance types and preferences within KubeVirt!
It’s been over two years since the last update, during which the instance type
and preference APIs have matured significantly. This update covers the major
milestones achieved between KubeVirt v1.0.0 and v1.7.0.
Please also feel free to file bugs or enhancements against
https://github.com/kubevirt/kubevirt/issues using the /area instancetype
command to label these for review and triage.
Major Milestones
Removal of instancetype.kubevirt.io/v1alpha{1,2}
As planned in the previous update, the deprecated v1alpha1 and v1alpha2 API
versions have been removed. Users should ensure they’ve migrated to v1beta1 before upgrading to recent KubeVirt releases.
Deployment of common-instancetypes from virt-operator
A long-awaited feature has landed - virt-operator now deploys the
common-instancetypes bundles directly. This eliminates the need for separate
installation steps and ensures that a standard set of instance types and
preferences are available out of the box.
The latest deployed version is v1.5.1, providing a comprehensive set of
instance type classes and OS-specific preferences.
New Instance Type Features
IOThreads Support
Instance types can now configure IOThreads for improved storage performance:
Instance types now support nodeSelector and schedulerName for fine-grained
scheduling control. The nodeSelector accepts any Kubernetes node labels
defined by cluster administrators:
Panic devices can now be configured through preferences for improved crash
diagnostics.
Firmware Preferences Update
PreferredEfi has been introduced to replace the deprecated PreferredUseEfi
and PreferredUseSecureBoot fields, providing a more flexible firmware
configuration mechanism.
Preferred Annotations
Similar to instance types, preferences can specify preferred annotations:
Support for upgrading ControllerRevisions to newer API versions has been
implemented, enabling seamless migration as the API evolves.
What’s Coming Next
The most significant upcoming change is the promotion of the API to v1,
planned for KubeVirt v1.8.0. This milestone is tracked through
VEP #17 and implemented
in PR #16598.
The instance type and preference APIs continue to evolve based on community
feedback. Check the KubeVirt issue tracker for upcoming enhancements and
contribute your ideas!
I had the pleasure of delivering the following talk in person this year at devconf in Brno.
There were some challenges with audio and my delivery was rusty at best but the presentation is hopefully understandable and useful for folks.
There were plenty of questions at the end of the talk and even more in the hallway/booth track outside the lecture hall. Feel free to comment on the post if you have more or reach out directly using my contact details on the opening slide.
Happy and slightly nervous to highlight that a talk submitted on my behalf by a wonderful colleague while I was out on sick leave was accepted for devconf.cz this year and I’ll be presenting in room D105 at 14:00 CEST on Thursday June 13th:
This has already allowed me to report bug #11749 regarding vCPUs being exposed as threads pinned to non-thread sibling pCPUs on hosts without SMT when using dedicatedCpuPlacement. It has also helped greatly with the design of SpreadOptions that aims to allow instance types users to expose more realistic vCPU topologies to their workloads through extending the existing PreferSpreadpreferredCPUTopology option.
I’m looking also at breaking up the KUBEVIRT_NUM_VCPU env variable to better control the host CPU topology within a kubevirtci environment but as yet I haven’t found the time to work on this ahead of the rewrite of vm.sh in go via PR #1164.
Feel free to reach out if you have any other ideas for kubevirtci or issues with the above changes! Hopefully someone finds this work useful.